
広告について。
サイト運営のため、Googleアドセンス
による広告があります。
Contents - 目次
ChatGPT GPT-4oの画像生成、Image Generation。
Image Generation(Image Gen)の使い方例。
作りたい画像をメッセージで指示。
生成したい画像をテキスト入力で指示。
(※テキストメッセージのことをプロンプトとも呼ばれる。)
現在は生成に結構、時間がかかる。(今回は無料プランで生成。)
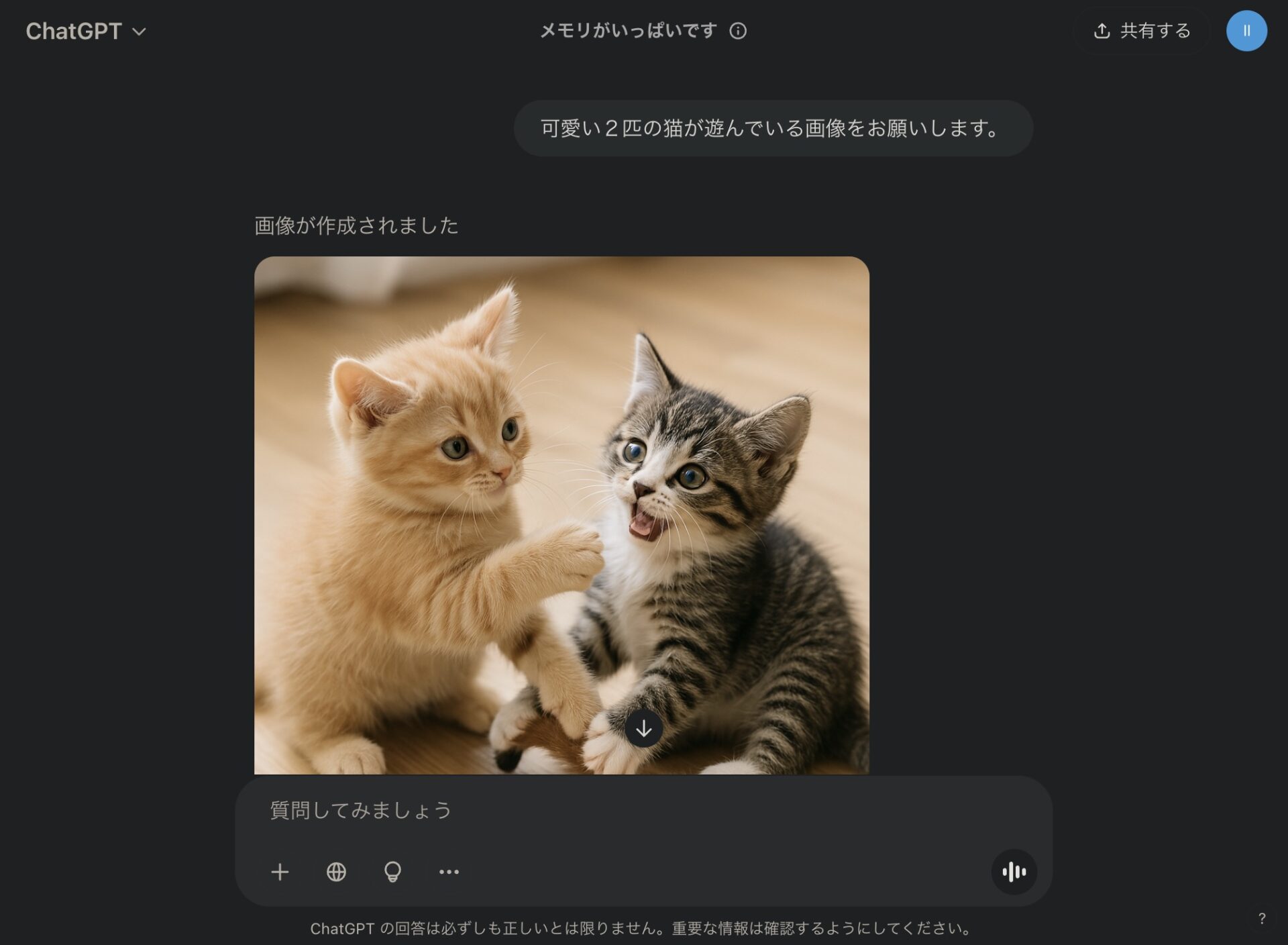
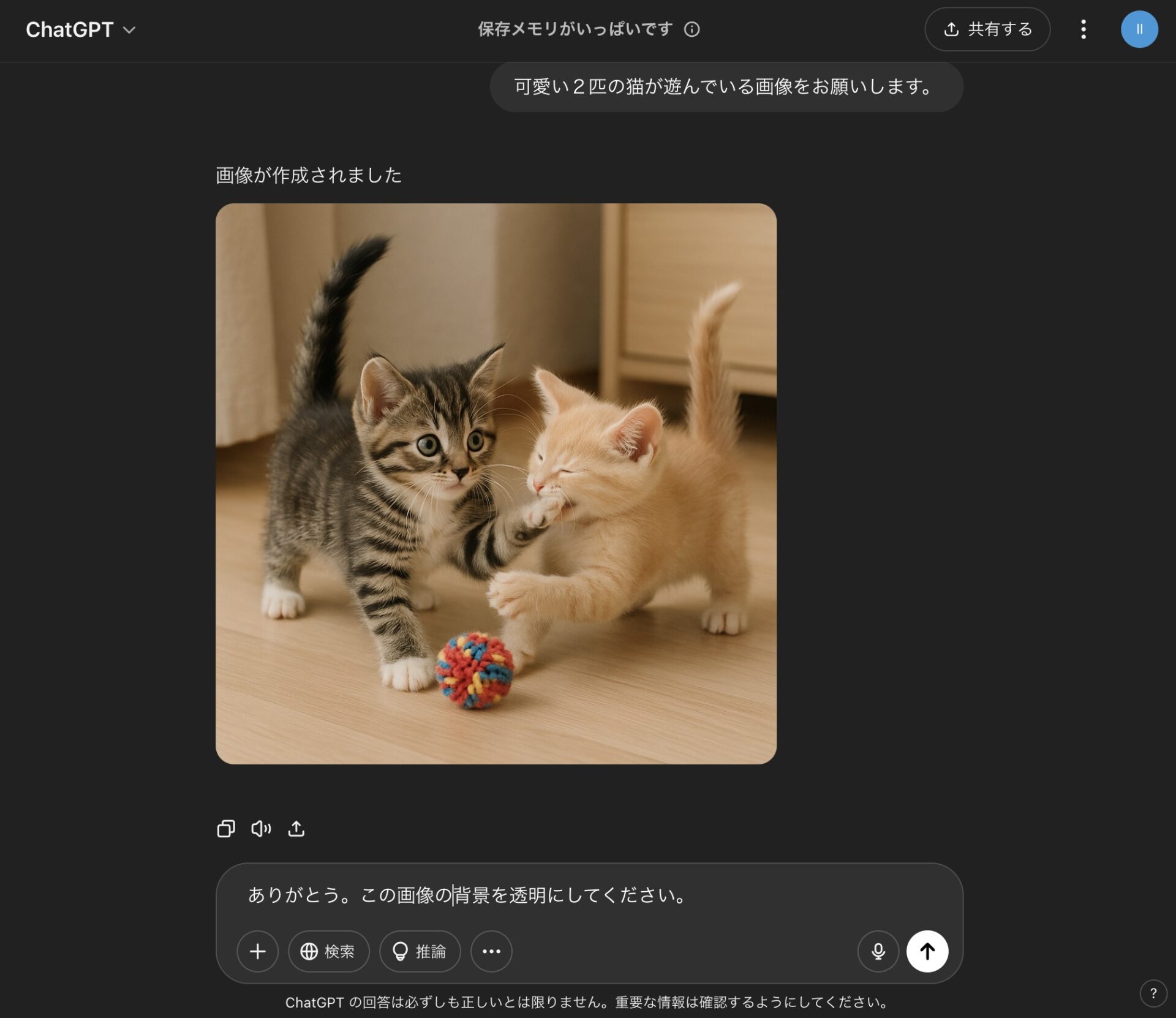
メッセージ(プロンプト):「可愛い2匹の猫が遊んでいる画像をお願いします。」
メッセージに応じた画像が生成される。
しばらく待つと画像ができあがる。
特にテイストなどを指示をしない限り、最初は写実的になる。
〇〇風に。
生成された画像に対して、追加で〇〇風にとお願いすると、さらに画像が生成される。
(※〇〇風などの画像生成は、年齢制限や著作権の問題に気をつけた方が良いかと思います。)
色の指定。
色指定の例。
画像の色については、16進数やカラーコード、HEXカラーなどと呼ばれる#(ハッシュ)記号の後に6桁の数値で指定ができる。
- 白:#ffffff
- 黒;#000000
- ターコイズブルー:#00afcc
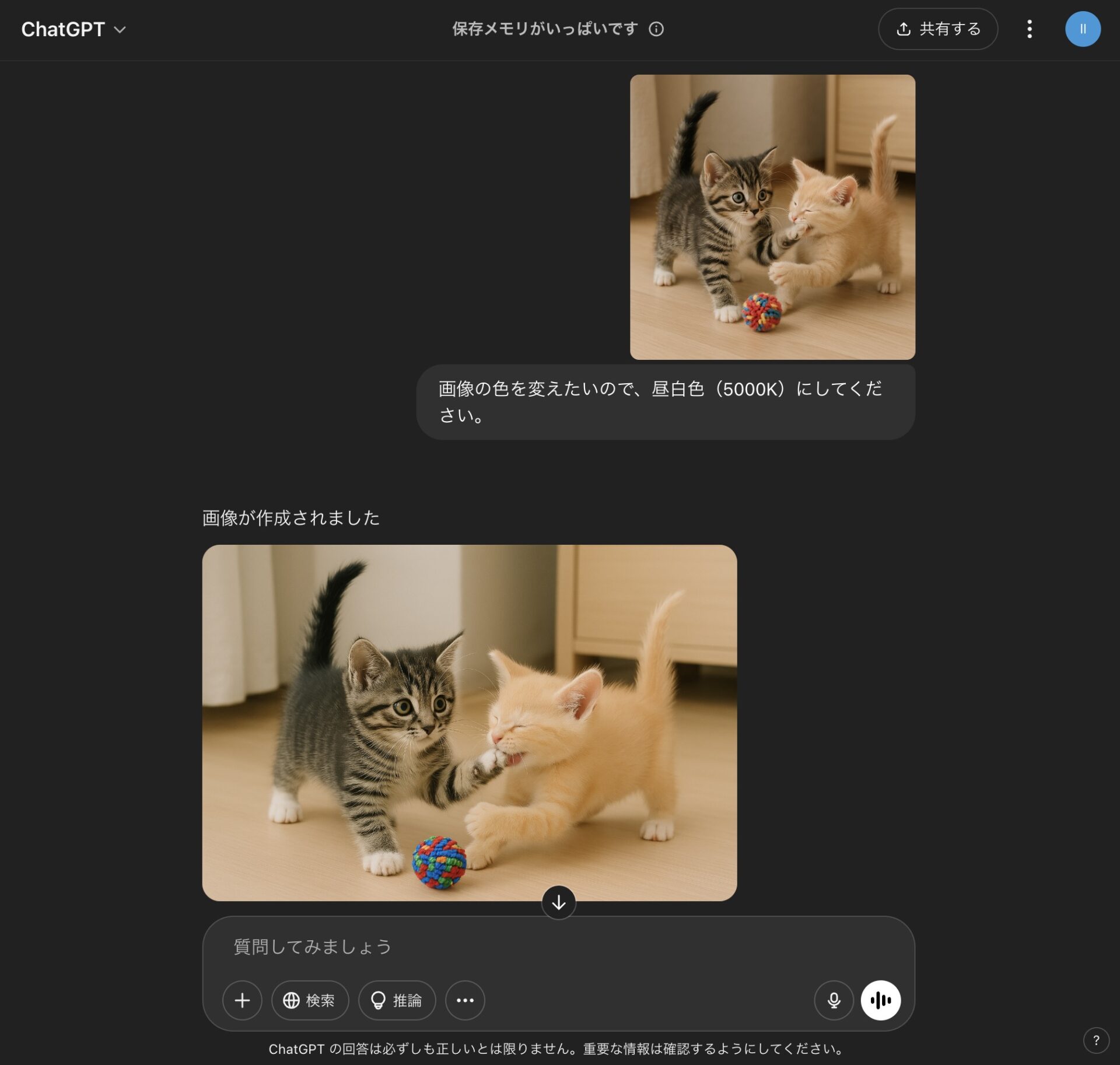
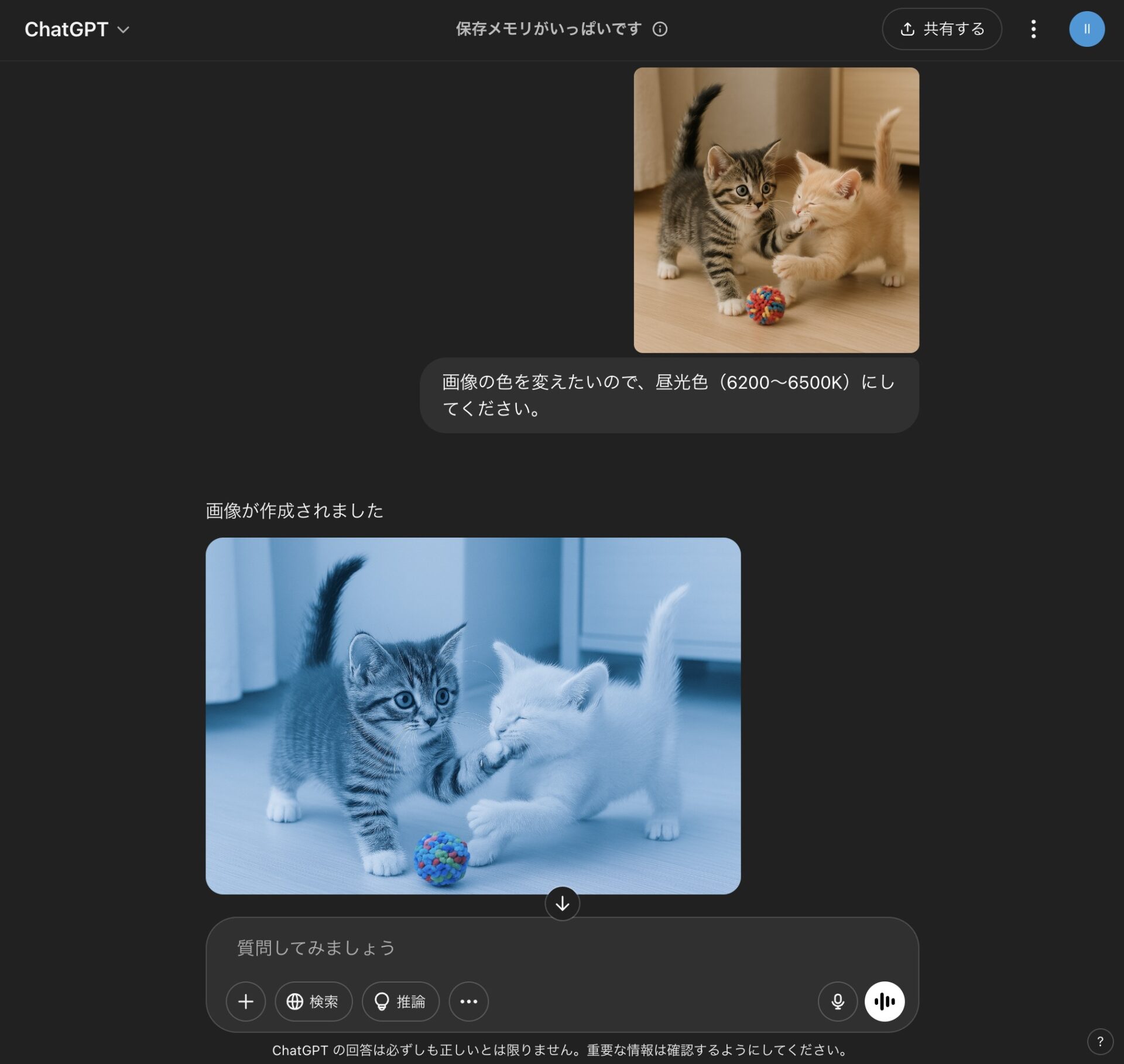
色温度の指定。
また、照明などで使用される単位のK(ケルビン)の数値で、色温度の指定ができる。
昼白色の例。
昼光色の例。
色温度について。
代表的な色温度について。(JIS規格)
- 電球色(でんきゅうしょく):2600~3250K(JIS)[例.2700K] 赤みがかったあたたかみのある光色。
- 温白色(おんぱくしょく):3250~3800K(JIS)[例.3500K] 電球色と昼白色の中間色で、ややあたたかみのある光色。
- 昼白色(ちゅうはくしょく):4600~5500K(JIS)[例.5000K] さわやかな白い光色。
- 昼光色(ちゅうこうしょく):5700~7100K(JIS)[例.6500K] 日中の自然光のような、青みがかった明るい印象の光色。
引用元:あかりに関する単語 | LED照明ナビ | JLMA 一般社団法人日本照明工業会
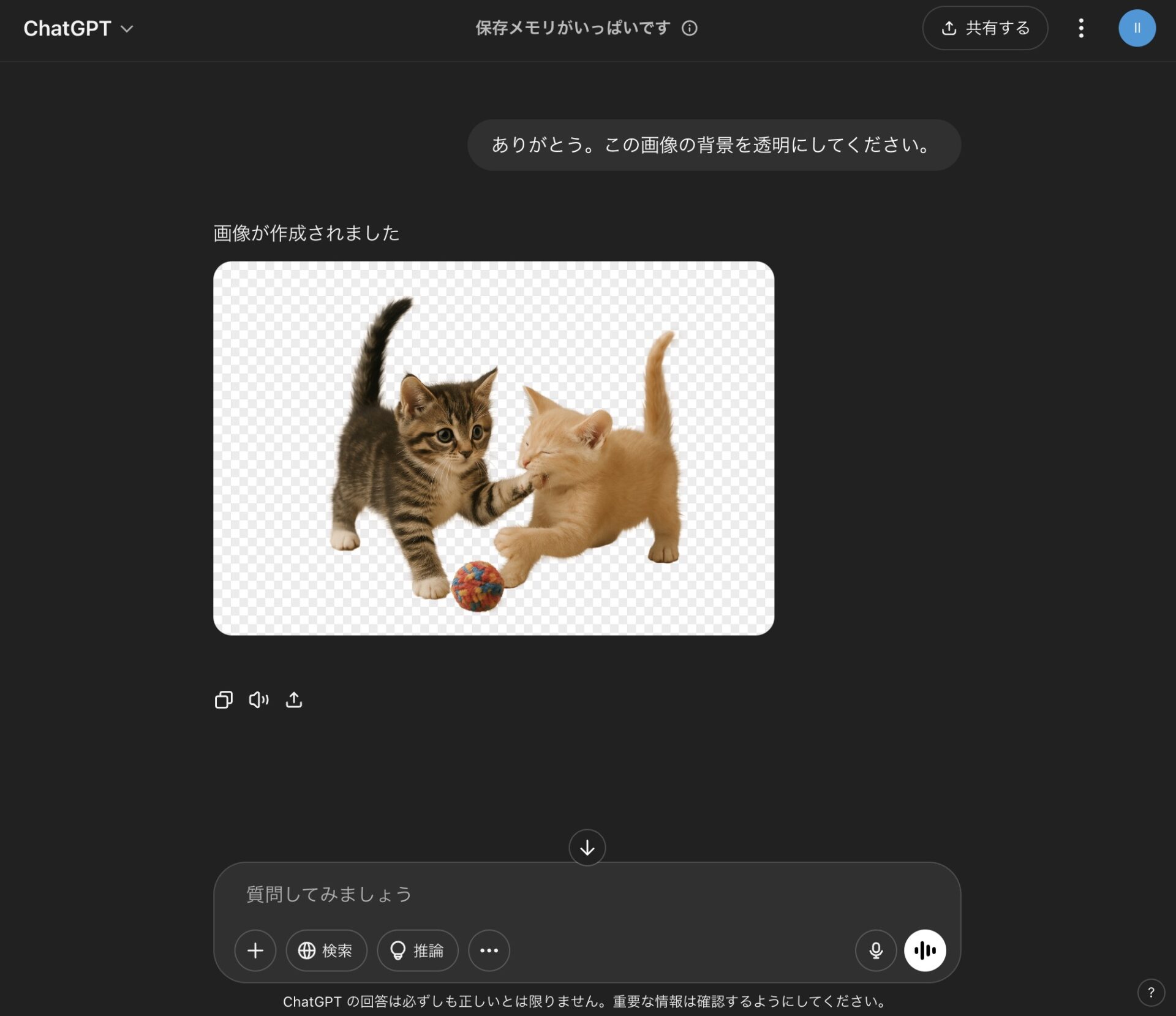
背景の透過。
被写体の背景を切り抜き。
透過の機能により、被写体の背景を削除することも可能。
背景が透過され、切り抜かれた画像となる。
ChatGPTで画像生成ができないとき。
画像生成の利用制限がかかっている。
利用制限されるほど混み合っている。
ChatGPTの新しい画像生成機能は無料ユーザーへも段階的に提供されている。
予想以上の人気。
ただし人気が高く、画像生成に時間がかかったり、制限がかかったりすることがある。
OpenAI COOのBrad Lightcap(ブラッド・ライトキャップ)さんによると、リリース後1週間で、1億3000万人以上のユーザーが7億枚以上の画像を生成したとこのこと。
very crazy first week for images in chatgpt – over 130M users have generated 700M+ (!) images since last tuesday
India is now our fastest growing chatgpt market 💪🇮🇳
the range of visual creativity has been extremely inspiring
we appreciate your patience as we try to serve…
— Brad Lightcap (@bradlightcap) April 3, 2025
画像生成に時間がかかっている。
無料プランでは生成枚数が少ない。
無料プランの場合、1日に数回ほどしか画像を生成できない。2025年4月初旬時点での目安は、修正を含めても3回程度。
ChatGPTに限らず、普通は同じサービスでも有料の方が優先される。混雑すると画像生成にも時間がかかる。
GPU(画像処理装置)や半導体チップへの影響。
CEOのSam Altman(サム・アルトマン)さんによると、画像生成に使用されるOpenAIのGPUに大きな負荷がかかっているとのこと。
it's super fun seeing people love images in chatgpt.
but our GPUs are melting.
we are going to temporarily introduce some rate limits while we work on making it more efficient. hopefully won't be long!
chatgpt free tier will get 3 generations per day soon.
— Sam Altman (@sama) March 27, 2025
ChatGPT 4o Image Generationのプロンプトについて。
ChatGPTへ、テキストメッセージ(プロンプト)でお願い。
次世代の、テキストから画像生成。
より具体的な指示出しをすると、信じられないほどの画像生成が可能となる。
デジタル画像は、ピクセルの集合体。そのピクセルへ対してRGBによる色指定と、X軸とY軸、Y軸での位置指定で構成される。
つまり、数値化ができ、数値によって画像を生成できる。
(※ChatGPTはあらかじめ学習しているため、画像生成に数値が必要ということではありません。)
画像内の文字が、大きく改善されている。
日本語では大量の漢字やカタカナ、ひらがながあるため、看板の文字や漫画のセリフなどに改善の余地があった。
それらが、大幅に改良されている。
英語の場合は少量のアルファベットで構成されているので、文字も含めて、もはや写真との区別もつかなくなってきている。
画像生成のプロンプト。4o Image Generation。
最初の指示出し。
OpenAIの画像生成(4o Image Generation)の例。
下記のメッセージ(プロンプト)はOpenAIのサイトのもの。
(※長いので、折りたたんでいます。)
参照元:Introducing 4o Image Generation | OpenAI
画像が生成される。
特にテイストなどを指示をしない限り、最初は写実的になる。

追加の指示出し。
画像が生成される。
もはや写真と見分けがつかない。
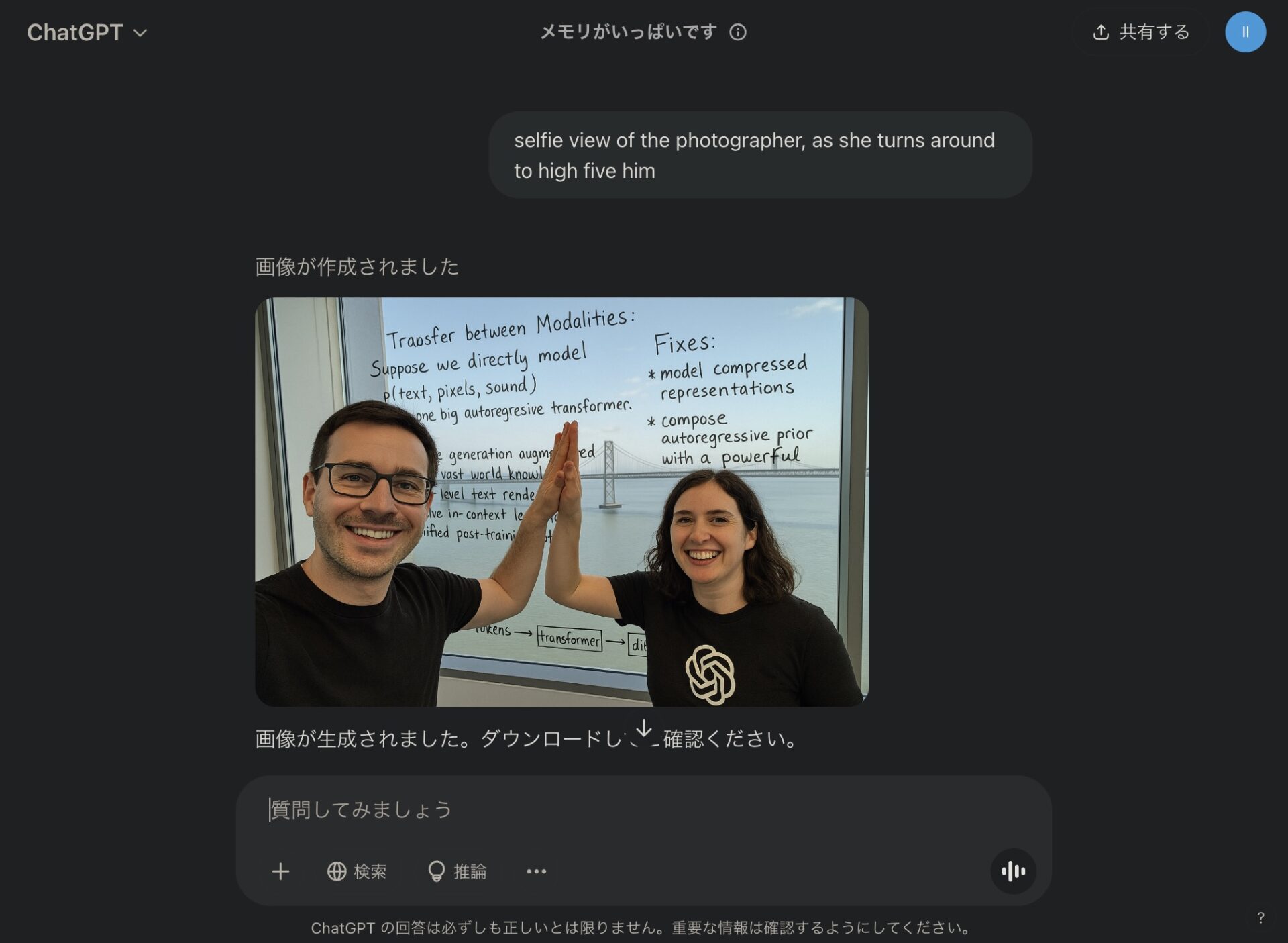
OpenAIのサイトでの生成画像との比較。
Generation。まさに次世代の生成。
同じメッセージだからと言って、生成された画像もまったく同じになるとは限らないことがわかる。
前後のチャットのやりとりや、日時や時間の影響もあると思われる。

ほとんど完璧なクオリティ。文字のテイストまで人間と区別がつかない。

言語化による指示出しが重要。
ChatGPTとプロンプトのやりとりをしてから。
画像生成は簡単だが、自分が欲しい画像を生成するためには、メッセージでどのような指示を出せるかによる。
ChatGPTはもともとLLM(大規模言語モデル)なので、メッセージのやりとりや、言語化に向いているAI。
そのため、最初は指示出し、言語化、それによるプロンプト作成の練習と、画像生成の繰り返しから始めると良いと思う。
ChatGPT生成画像の利用と目的。
AI生成画像の利用価値。
AIによる生成画像は比較的簡単にできるので、プライベートや仲間内での思い出作りや共有がしやすい。
ただしビジネス目的の場合、それだけでは「価値」がつかないことも想定される。
単純に数枚の画像で「対価」を求めるのは難しいと思われる。
無料プランではハードすぎる。
無料プランの場合は制限が厳しいので、1日に数枚ほどしか画像を生成できない。
これは格差社会の問題であり、不公平が生まれるが、人類の歴史から見ても改善の見込みはなかなかない。
無料プランでは勝負にならないので、他のサブスクなどの固定費をChatGPTの有料プランに回すか、方向転換した方が良いかと思う。
商用利用や年齢制限について。
商用利用について。
利用規約(Terms of use)。
AIの生成画像については現時点、ガイドラインや法律が追い付いていないような状況のため、使用には注意が必要。
下記からOpenAIの利用規約を確認できる。
参照元:利用規約 | OpenAI
参照元:使用に関するポリシー | OpenAI
年齢制限について。
ChatGPTの年齢制限。
OpenAIの利用規約のページによると、使用するためには13歳以上、または住んでいる国で定められる最低年齢に達している必要があり、18歳未満の場合は親または法定後見人の許可がいる。
参照元:利用規約 | OpenAI
生成画像の注意点。
フェイク画像やフェイク動画拡散の恐れ。
写真のようなリアリティのあるものも生成され、明らかに〇〇風の画像も生成されるので、SNSなどでのフェイクや、著作権などに気をつけていくような時代になると思われる。
あくまでも常識の範囲内で。
現時点、無断でクリエイターの作品を学習させることへは賛否両論があり、著作権や肖像権などの法の整備も追いついていない。
作者への敬意や配慮、場合によっては対価が必要で、その方が倫理的、道徳的にも好ましいかと。
プライベートとパブリックの区別が無難。
自分のスマホやパソコンの壁紙、待ち受けに使用するのと、SNSなど公の場で公開するのでは大きく違う。
(※服を着ずに街中を歩くと捕まるように。)

以上、参考になれば幸いです。
※Webデザインは実務数年、職業訓練校講師数年、フリーランス数年、計15年以上のキャリアがありますが、一気にがぁっと書いているので「です・ます調」ではありません。(元々はメモ書きでした。) ※事実や経験、調査や検証を基にしていますが、万一なにかしら不備・不足などがありましたらすみません。お知らせいただければ訂正いたします。 ※写真は主にUnsplashやPixabayのフリー素材を利用させていただいております。その他の写真や動画もフリー素材やパブリックドメイン、もしくは自前のものを使用しております。
井川 宜久 / Norihisa Igawa

AI 関連メモ。
ChatGPT 関連メモ。
- Gemini 3。アプリや検索、Google AI Studioで無料でも使える最新モデル。
- ChatGPTの性格設定。パーソナライズで会話をしやすいように。
- ChatGPT(チャットGPT)を4oに戻したいとき。無料でもGPT-4o風に。
- ChatGPT最新「GPT-5」の性能。有料ユーザーから無料ユーザーへ。
- ChatGPTだけで被写体背景の切り抜き、背景色を変更する方法。
- ChatGPT 4o Image Generationの使い方の例。画像生成ができないとき。
- ChatGPTの最新推論モデル「o3-mini」の使い方とヒント。
- ChatGPTの次世代モデル、GPT-4.5とGPT-5のリリース時期と可能性。
- ChatGPTの最新推論モデル「o3-mini」の使い方とヒント。
- ChatGPT searchとは?使い方や、有料と無料、Googleとの違い。
- Chrome拡張機能、ChatGPT searchの使い方。自然言語、日常会話で検索。
- ChatGPTに検索機能。ChatGPT searchでWeb検索が可能に。
- MacとWindowsでもChatGPTと音声会話。Advanced Voiceが利用可能に。
- Advanced Voiceによる音声会話。ChatGPTとプラトニックな関係に?
- OpenAI o1の使い方。考えてから答える新しいChatGPTモデル。
- Voice Engineという名の、音声合成技術。日本語の精度は?
- SearchGPT。ChatGPTがAI検索エンジンに。使い方の例と順番待ちへの登録方法。
- GPT-4o miniが登場。ChatGPT無料版はGPT-3.5からバージョンアップ。
- ChatGPT無料ユーザーにもメモリ機能が。記憶や使い方の例。
- iPhoneやiPad、MacでChatGPT(GPT-4o)が。Apple Intelligence。
- 生成AIとWebデザイン、ChatGPTを活用したコーディングに必要なもの。
- ChatGPT最新モデル GPT-4oが無料でも。使える主な機能。
- ChatGPT(GPT-4o)で、PDF要約の精度を検証した結果。
- GPT-4o。ChatGPTと画像見ながら音声で会話?有料でも無料でも。
- ChatGPT無料版でも画像生成が可能に。有料版だけじゃない!?
- ChatGPT(チャットGPT)にアーカイブ機能が。復元も削除も。
- ChatGPT(チャットGPT)を日本語化。日本語設定の方法。
- ChatGPT(チャットGPT)との音声会話と、音声の変更方法。
- ChatGPTアプリのインストールとログイン方法、チャットの使い方。
- ChatGPT(チャットGPT)のスペルチェック、文章校正がむっちゃ楽。
- ChatGPT(チャットGPT)へのログイン方法。ログインできないとき。
- ChatGPTにプラグイン。広がる機能と使い方。最新情報へも。
- ChatGPTがLINEに?「AIチャットくん」の始め方、そして使い方。
- ChatGPTの始め方と使い方と。初心者向けシンプル版。
- ChatGPTはSVGアイコンを作れるのか?
- ChatGPTの文章作成やコーディング、SEO対策は変わるか?
Gemini 関連メモ。
- Geminiで画像の作成や編集。人物や写真、イラストの商用利用と注意点。
- Gemini 2.5 Proがアップグレード。Google AI Studio無料プランの使い方。
- Deep Researchというリサーチツール?無料で使えるGoogle Gemini。
- GeminiアプリがiOSにも。Googleアプリからはアクセス不可に。
- ChatGPTやGeminiなど生成AIの年齢制限と、AI使用のリスク。
- NotebookLMは使えない?YouTube動画とPDFの使い方と検証結果。
- Google AI Studioの「Gemini 1.5 Pro 002とGemini Experimental 1114」にできること。
- ChromeがGoogle レンズで検索、アドレスバーからGeminiの利用が可能に。
- Gemini 1.5 Pro 2Mモデル。Waitlistの登録手順。日本語上手なGoogle生成AI。
- BardからGeminiに。使い方はどう変わる?日本語対応は?
- Gemini(旧Bard)が絵を描けるように。テキストから画像生成の方法。
- Gemini(旧Bard)の画像認識の使い方。日本語対応済み、Googleレンズで画像読み取り。
- 最新情報を日本語かつ無料で使いたいときは、GoogleのBard?
- ChatGPTとBardの違い。なぜAIは日本語チャットが苦手なの?
- Bard(Gemini)が日本語対応。ログイン方法や最新情報など、使い方の例。
- BardでGemini。Googleの最新AIを無料で使う方法。
- GoogleのBardは、OpenAIのChatGPTを越えられるだろうか?
Copilot、Bing 関連メモ。
- ChatGPTとCopilotの違い。料金や、できることと、できないこと。
- Copilotとは? GPT-4とDALL·E 3が無料で使える生成AI。
- SkypeのBingチャット。GPT-4を日本語かつ無料で使える。& 注意点。
- BingのGPT-4、チャットの使い方。使えない?(今はまだ。)
- MacでGPT-4(ChatGPT最新版)を使う場合、Edgeが必要なのかも。
Llama 関連メモ。
- Llama 3.1登場。MetaのオープンソースAIとダウンロードサイト。
- Meta Horizon OSとApple Vision Pro。オープンかクローズか。
- Llama 3。無料でオープンソースなMeta AI最新モデル。
- Llama(ラマ)の使い方や日本語は? ダウンロード手順とブラウザ実装サイト。